Abstract
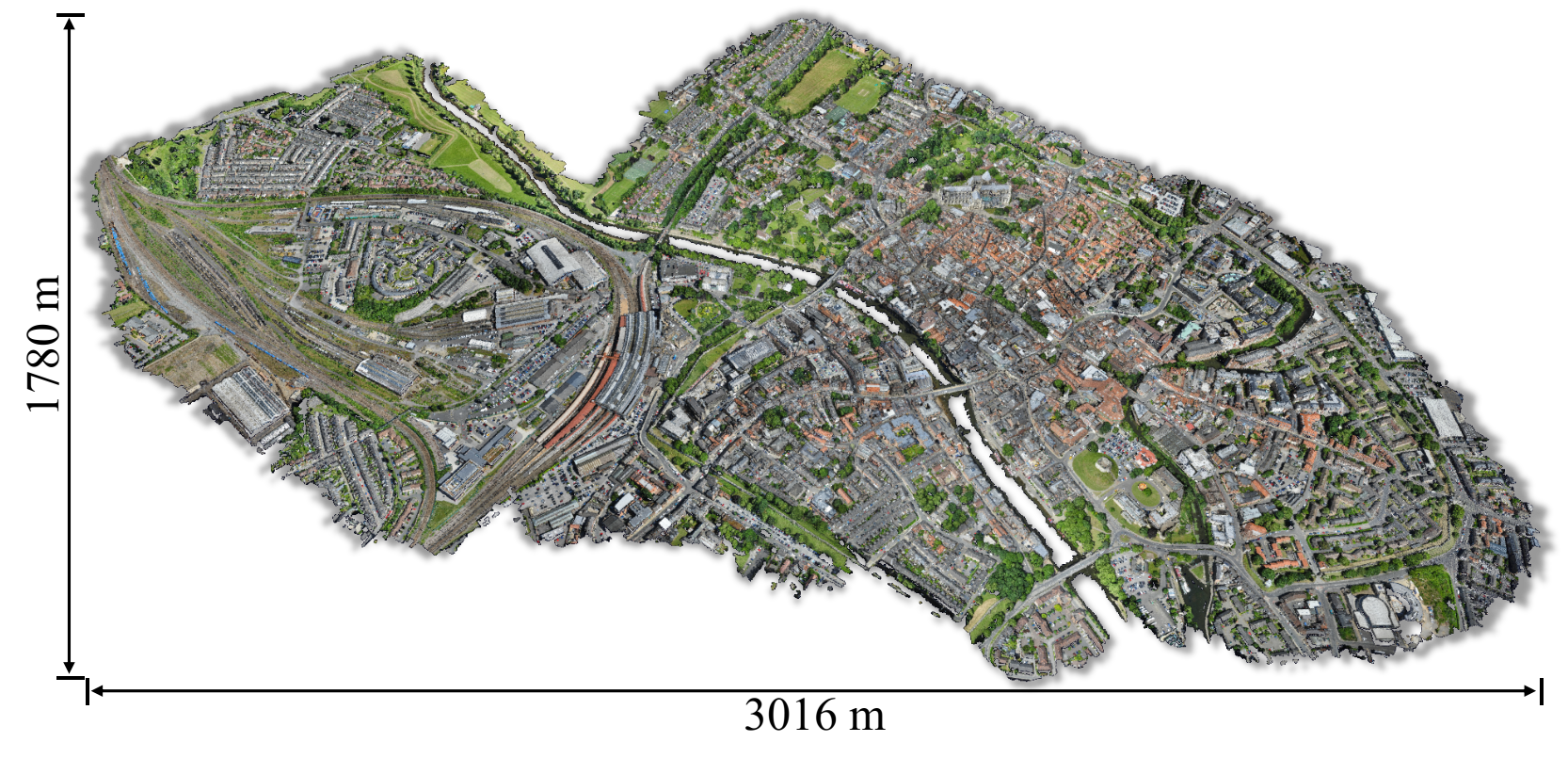
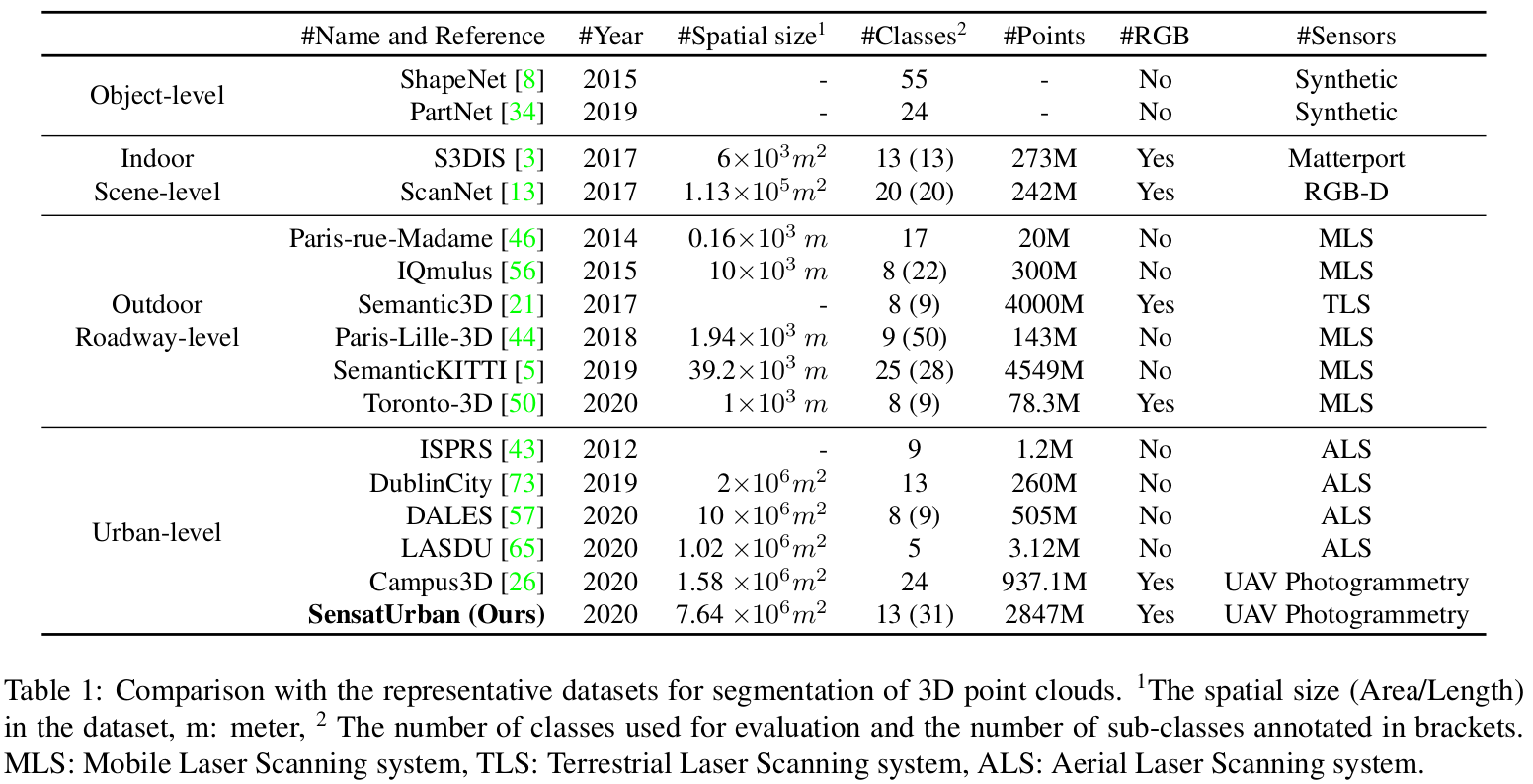
An essential prerequisite for unleashing the potential of supervised deep learning algorithms in the area of 3D scene understanding is the availability of large-scale and richly annotated datasets. However, publicly available datasets are either in relative small spatial scales or have limited semantic annotations due to the expensive cost of data acquisition and data annotation, which severely limits the development of fine-grained semantic understanding in the context of 3D point clouds. In this paper, we present an urban-scale photogrammetric point cloud dataset with nearly three billion richly annotated points, which is five times the number of labeled points than the existing largest point cloud dataset. Our dataset consists of large areas from two UK cities, covering about 6 km² of the city landscape. In the dataset, each 3D point is labeled as one of 13 semantic classes. We extensively evaluate the performance of state-of-the-art algorithms on our dataset and provide a comprehensive analysis of the results. In particular, we identify several key challenges towards urban-scale point cloud understanding.Overview
Data Collection
Due to the clear advantages of UAV imaging over similar mapping techniques, such as LiDAR, we use a cost effective fixed wing drone, Ebee X, which is equipped with a cutting-edge SODA camera, to stably capture high-resolution aerial image sequences. In order to fully and evenly cover the survey area, all flight paths are pre-planned in a grid fashion and automated by the flight control system (e-Motion). Note that, the camera has the ability to take both oblique and nadir photographs, ensuring that vertical surfaces are captured appropriately. Since each flight lasts between 40-50 minutes due to limited battery capacity, multiple individual flights are executed in parallel to capture the whole area. These multiple aerial image sequences are then geo-referenced using a highly precise onboard Realtime Kinemtic (RTK) GNSS. Ground validation points which are measured by independent professional surveyors with high precision GNSS equipment are then used to assess the accuracy and quality of the data. For illustration, Following figure shows the paths of the pre-planed multiple flights to cover the selected area in the Cambridge city.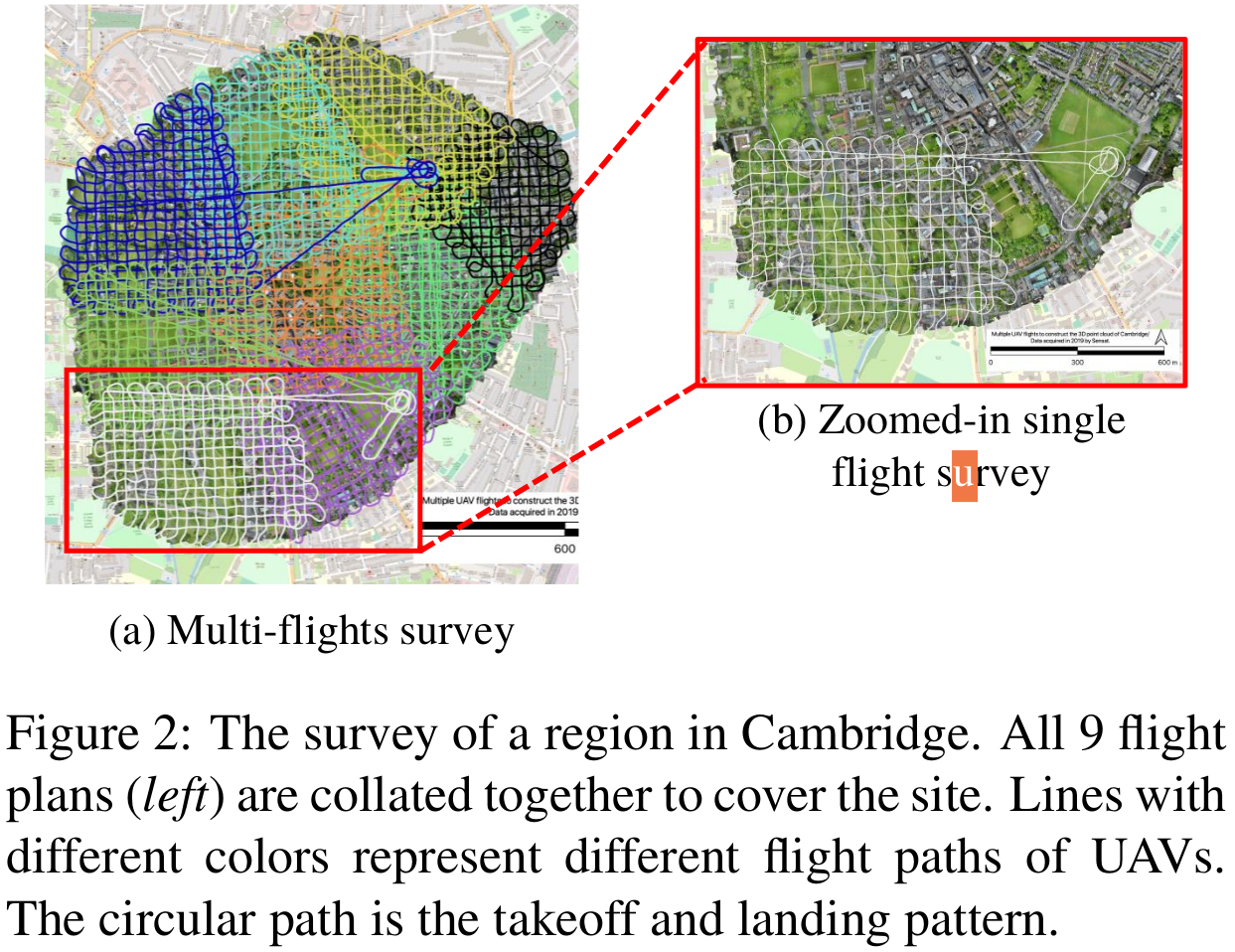
Semantic Annotation
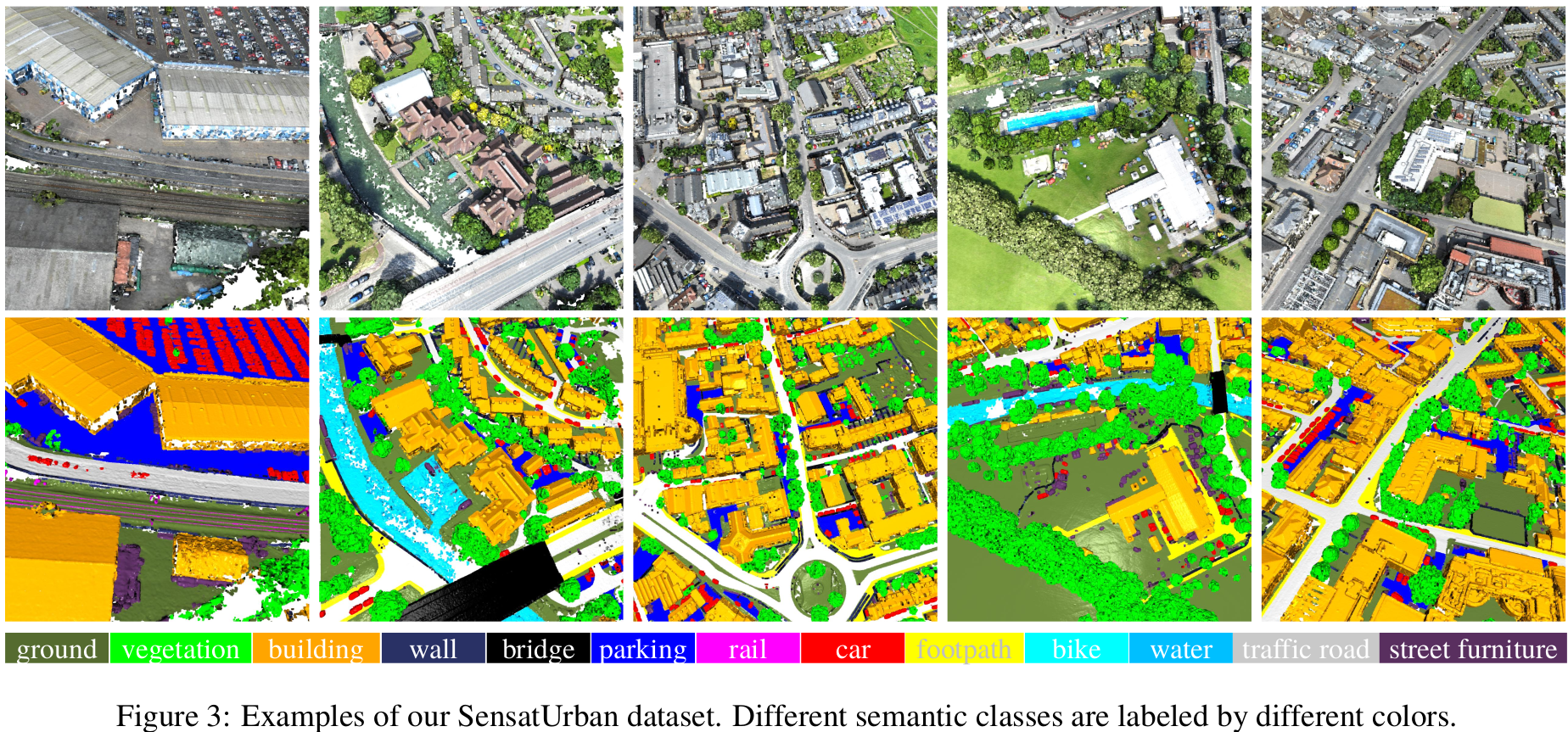
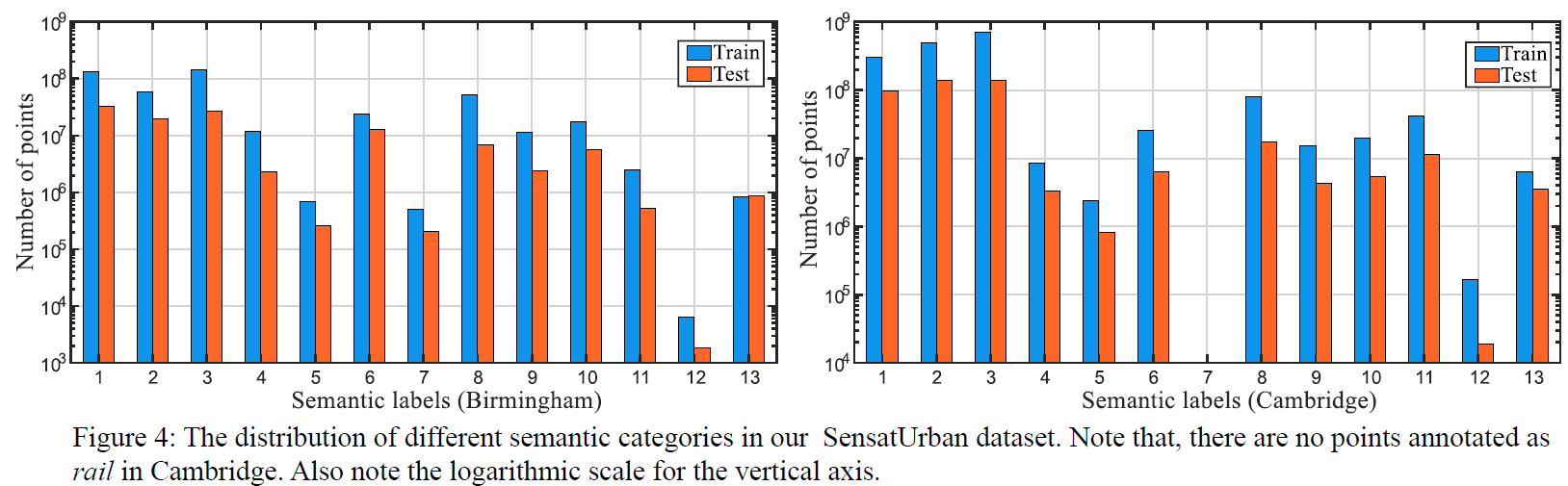
We identify the below 13 semantic classes to label all 3D points via off-the-shelf point cloud labeling tools. All labels have been manually cross-checked, guaranteeing the consistency and high quality.- Ground: including impervious surfaces, grass, terrain
- Vegetation: including trees, shrubs, hedges, bushes
- Building: including commercial / residential buildings
- Wall: including fence, highway barriers, walls
- Bridge: road bridges
- Parking: parking lots
- Rail: railroad tracks
- Traffic Road: including main streets, highways
- Street Furniture: including benches, poles, lights
- Car: including cars, trucks, HGVs
- Footpath: including walkway, alley
- Bike: bikes / bicyclists
- Water: rivers / water canals
Benchmark results
We carefully select 7 representative methods assolid baselines to benchmark our SensatUrban dataset. That is, SparseConv, TagentConv, PointNet, PointNet++, SPGraph, KPConv, RandLA-Net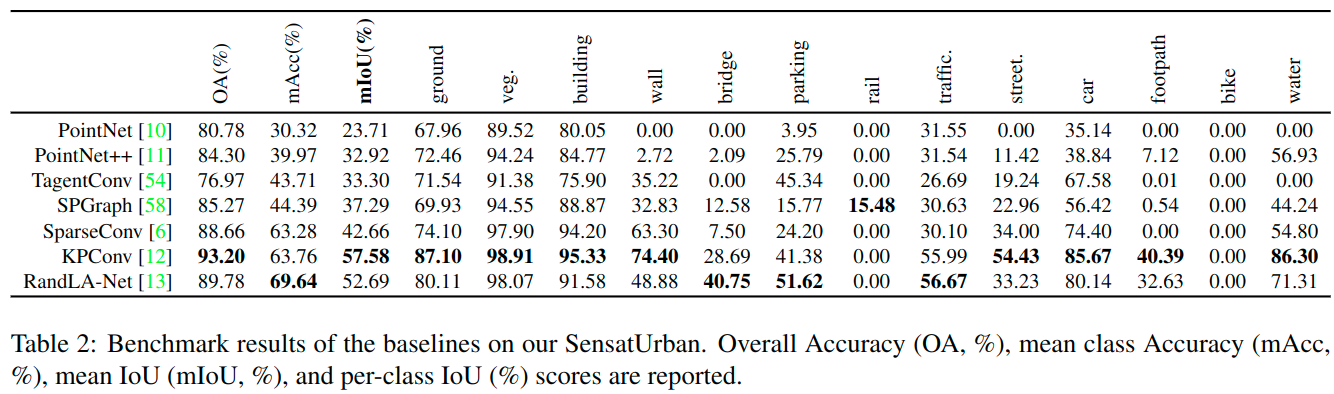
Demo
Publications
CVPR, 2021